Análisis de Espectro Completo: El Método Óptimo para Monetizar la Información
2025-08-10
Antecedentes
¿Cómo maximizar la tasa de crecimiento de los activos?
En 1956, J.L. Kelly publicó "A New Interpretation of Information Rate" (Una nueva interpretación de la tasa de información). El artículo discute cómo un apostador puede utilizar información conocida para maximizar la tasa de crecimiento compuesto de sus activos. Propone un método probabilístico para guiar la estrategia de apuestas. Sin embargo, la aplicación de este artículo a actividades de inversión reales presenta varios problemas:
- No utiliza apalancamiento mediante préstamos ni ventas en corto, por lo que sus conclusiones se mantienen dentro del rango de apalancamiento real de 0 a 1.
- Supone que el apostador apuesta por un símbolo de evento, y si ocurre en la siguiente ocasión recibe un pago; de lo contrario, pierde su apuesta. Pero los operadores solo pueden apostar a largo/corto, y los eventos de subida/bajada correspondientes a estas posiciones presentan resultados y rendimientos diferentes en diferentes ventanas de tiempo.
- Momento de liquidación: Kelly supone que la liquidación de la apuesta no depende de la voluntad del apostador. Pero los operadores pueden decidir salir o mantener la posición en cualquier momento.
- Método bayesiano redundante, que supone que el desarrollo de los eventos está relacionado con probabilidades previas y condicionales anteriores. Eliminar el método bayesiano no afecta la esencia matemática derivada. Aumenta la dificultad, y la aplicación directa de la fórmula del artículo es compleja, requiriendo simplificación para su uso práctico.
Continuaremos utilizando el método probabilístico del artículo de Kelly para explorar una estrategia práctica aplicable al campo de la inversión y el trading.
Análisis de Espectro Completo: Full-Spectrum Analysis, FSA
Espacio de Resultados, Apalancamiento Óptimo y Rendimiento Óptimo
Supongamos que al implementar una estrategia de trading, eventualmente habrá varios eventos de resultado diferentes. Sea el espacio de resultados . no está vacío (en escenarios reales, existen al menos 2 resultados).
Hagamos algunas suposiciones adicionales:
- Rendimiento Determinista: Cada evento de resultado corresponde a un rendimiento específico. Sea el rendimiento del resultado .
- ✅ Eventos con diferentes rendimientos deben considerarse como eventos de resultado diferentes, por ejemplo, una ganancia del 1% y una ganancia del 2% son diferentes.
- ❌ Agrupar eventos de ganancia con rendimientos claramente diferentes en el mismo resultado viola el rendimiento determinista.
- Probabilidad Determinista: Sea la probabilidad de que ocurra el resultado ().
- ✅ La probabilidad de cada resultado debe evaluarse de manera determinista.
- ❌ Considerar que la posibilidad de que ocurra un resultado es superior al 80%: 80% ~ 100%, viola la probabilidad determinista.
- Exclusividad Mutua: Es imposible que ocurran 2 resultados simultáneamente.
- ✅ Se deben diseñar eventos de resultado que sean completamente mutuamente excluyentes.
- ❌ Si los eventos de resultado tienen intersección, por ejemplo, "mantener posición durante 20 minutos" y "caída del 20%" pueden ocurrir simultáneamente, se viola la exclusividad mutua.
- Exhaustividad: La suma de las probabilidades de todos los resultados es del 100%, no existen resultados fuera de los predefinidos, es decir, .
- ✅ Se deben considerar todos los resultados posibles.
- ❌ Si los eventos de resultado solo definen "subida superior al 20%", "caída superior al 20%", pero no definen "movimiento entre -20% y 20%", se viola la exhaustividad.
- Efecto de Apalancamiento: El rendimiento sigue el efecto de apalancamiento, es decir, si se utiliza un apalancamiento de veces, cuando ocurre el resultado , el rendimiento es , lo que significa que el activo se convierte en veces el original.
- ✅ La mayoría de los instrumentos de inversión con suficiente liquidez cumplen esta característica.
- ❌ Cuando el tamaño de la posición es demasiado alto, debido a problemas de liquidez, se generan costos de impacto de mercado y el rendimiento ya no sigue una relación lineal.
Para el espacio de resultados , podemos calcular su Rendimiento Esperado (Expected Earning Yield):
El concepto de rendimiento esperado es bastante intuitivo y fácil de calcular. El problema del rendimiento esperado es:
- Conduce a decisiones extremas: o posición cero o posición máxima, sin poder controlar el riesgo de ruina. Si el rendimiento esperado es positivo, tenderá a amplificar el apalancamiento infinitamente para buscar un mayor rendimiento, incluso si un alto apalancamiento puede llevar a la ruina.
- No considera el efecto del interés compuesto. Solo considera el rendimiento de una inversión única, no considera que el mercado permite inversiones repetidas. No se ajusta a la realidad de la gestión de inversiones.
El Rendimiento Compuesto (Compound Earning Yield) se refiere al rendimiento promedio por operación después de realizar múltiples operaciones independientes y repetidas:
El Rendimiento Óptimo (Optimal Earning Yield) es el valor máximo del rendimiento compuesto bajo diferentes niveles de apalancamiento:
Para evitar la ruina (llegar a cero), se debe satisfacer que para todos los resultados, . Esto conduce a un dominio factible básico para , denotado :
Límite superior:
Límite inferior:
Y una solución siempre factible ,
El apalancamiento óptimo es el valor de dentro del dominio factible que maximiza el rendimiento compuesto .
En cualquier momento, se puede calcular el apalancamiento real de la cuenta: , y también evaluar el apalancamiento óptimo: . Todas las estrategias de trading eventualmente corresponden a un apalancamiento real. Tomar una decisión de trading determinista equivale a decidir el valor de . Y el apalancamiento óptimo corresponde a la posición ideal.
Así, obtenemos un marco de trading:
- Diseñar el espacio de resultados .
- Evaluar continuamente las probabilidades de los diferentes resultados.
- Calcular el apalancamiento real y el apalancamiento óptimo .
- Controlar que el apalancamiento real se acerque al apalancamiento óptimo.
Puntos Especiales
Punto trivial: , es decir, "sin participación, no hay ganancias ni pérdidas". Cuando no tenemos posición, es equivalente a decidir establecer . Para cualquier instrumento, con o sin posición, estamos tomando decisiones en cada momento. Venta en corto corresponde al caso ; si , significa que se necesita apalancamiento adicional.
Resolución de la Optimización
Repasando el problema: conocido el espacio de resultados , la distribución de probabilidad , el rendimiento , el dominio factible , encontrar la tasa de apalancamiento que maximice el rendimiento:
Reorganizando el rendimiento compuesto, tomando logaritmos en ambos lados (preservando la monotonicidad), obtenemos:
Sea
Según la definición de apalancamiento óptimo:
Dado que es monótonamente creciente:
Calculando la primera y segunda derivada de :
Cada término en la segunda derivada es no positivo, por lo tanto . Solo cuando , , y en ese caso, , no hay rendimiento, carece de significado práctico. En otros casos, . Esto significa que es una función estrictamente cóncava, y es estrictamente monótona decreciente. tiene un único punto máximo, y este punto máximo es también el punto de valor máximo.
Como se muestra en la siguiente figura, independientemente del número de términos, la curva de es cóncava.
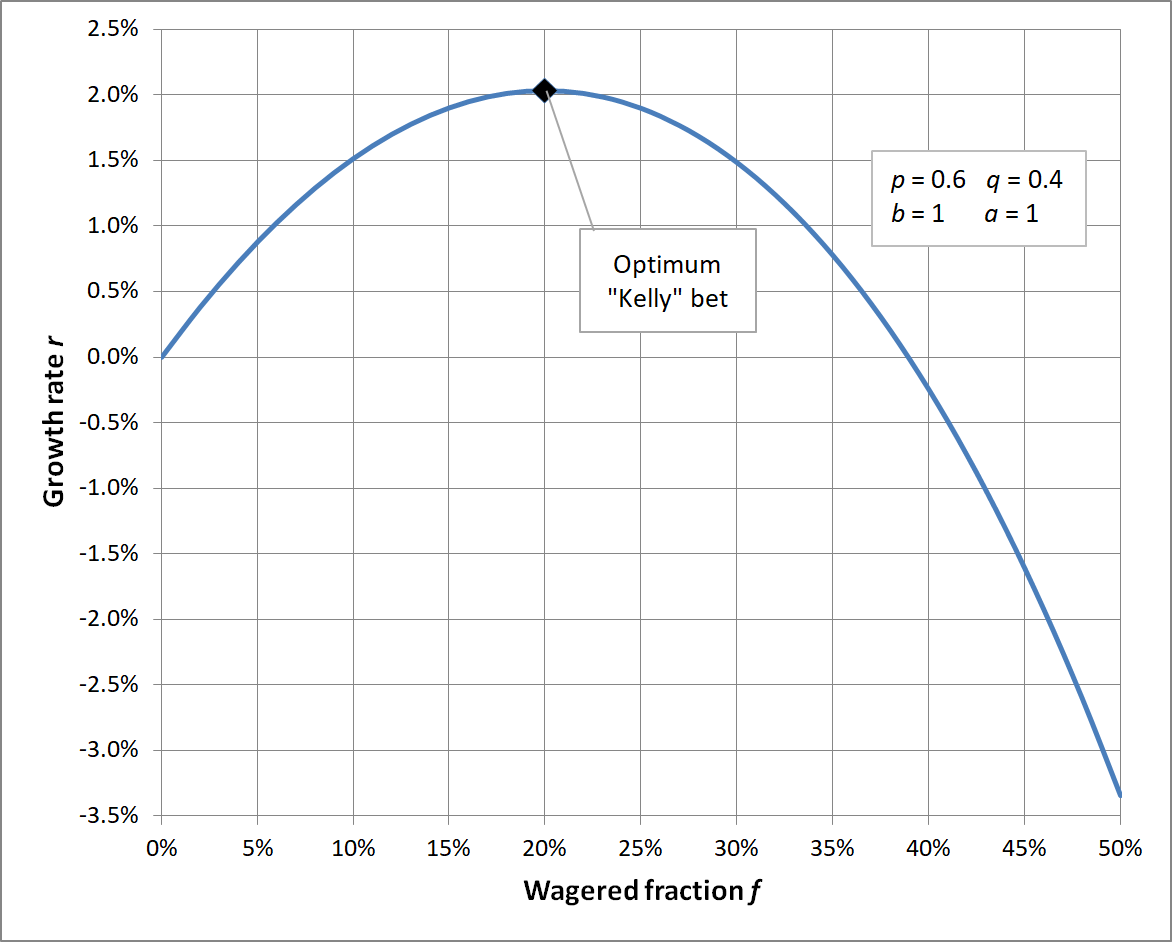
El punto máximo de es el cero de su primera derivada:
Si reorganizamos esta ecuación, se puede transformar en una ecuación polinómica en k. Si existen valores diferentes para , el grado máximo del polinomio resultante es . Según el teorema de Abel-Ruffini, los polinomios de grado cinco o superior no tienen una fórmula general para sus raíces.
La fórmula de Kelly común es un caso especial con : Sea la probabilidad de ganar, la cuota de pago.
| Resultado | Probabilidad | Rendimiento |
|---|---|---|
| Ganar | ||
| Perder |
Sustituyendo obtenemos la ecuación:
Reorganizando se obtiene
Que es la fórmula de Kelly.
Para escenarios de trading, pueden existir innumerables resultados con diferentes rendimientos, por lo que solo se pueden buscar soluciones numéricas.
Como función estrictamente cóncava de una variable, el método de Newton es la elección óptima. Comenzar la iteración desde el punto fijo es una buena opción; para una función estrictamente cóncava, comenzar desde cualquier punto convergerá al mismo resultado.
Situación donde el Método de Newton sale del Dominio Factible
Un problema potencial es que el punto de iteración obtenido por el método de Newton puede salir del dominio factible del problema. Usemos un ejemplo mínimo para ilustrar esta situación:
Obtenemos
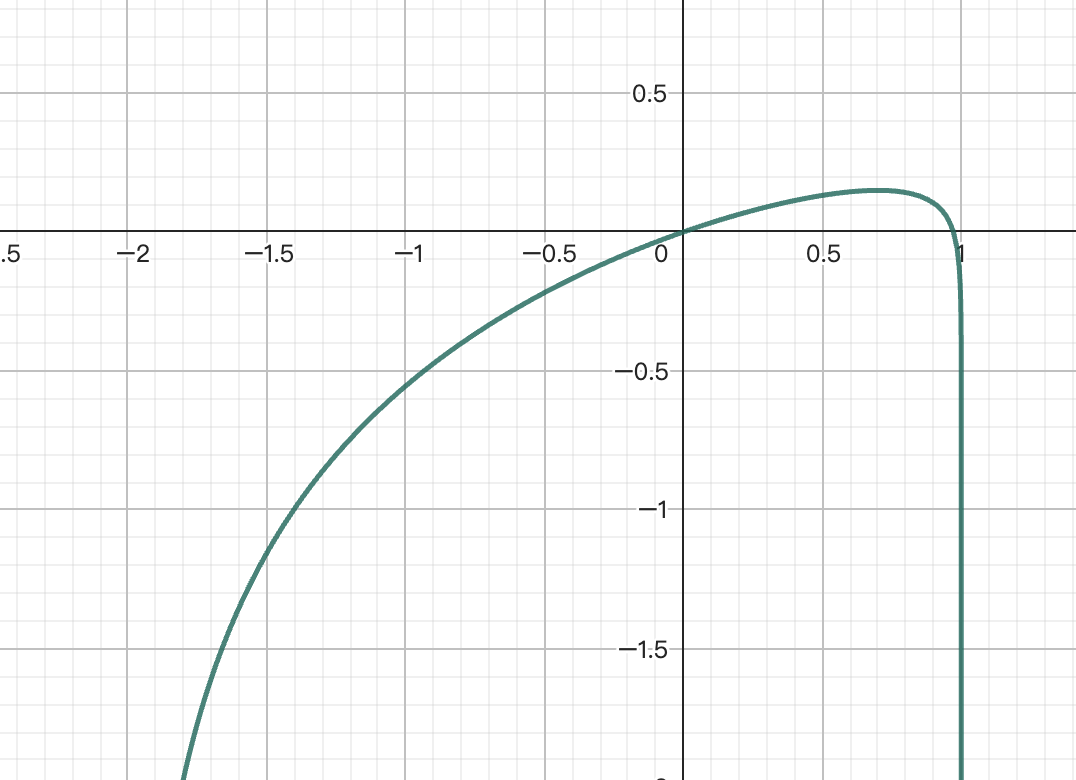
Cálculo muestra que el dominio factible , con apalancamiento óptimo analítico , pero al usar el método de Newton, el primer punto de iteración
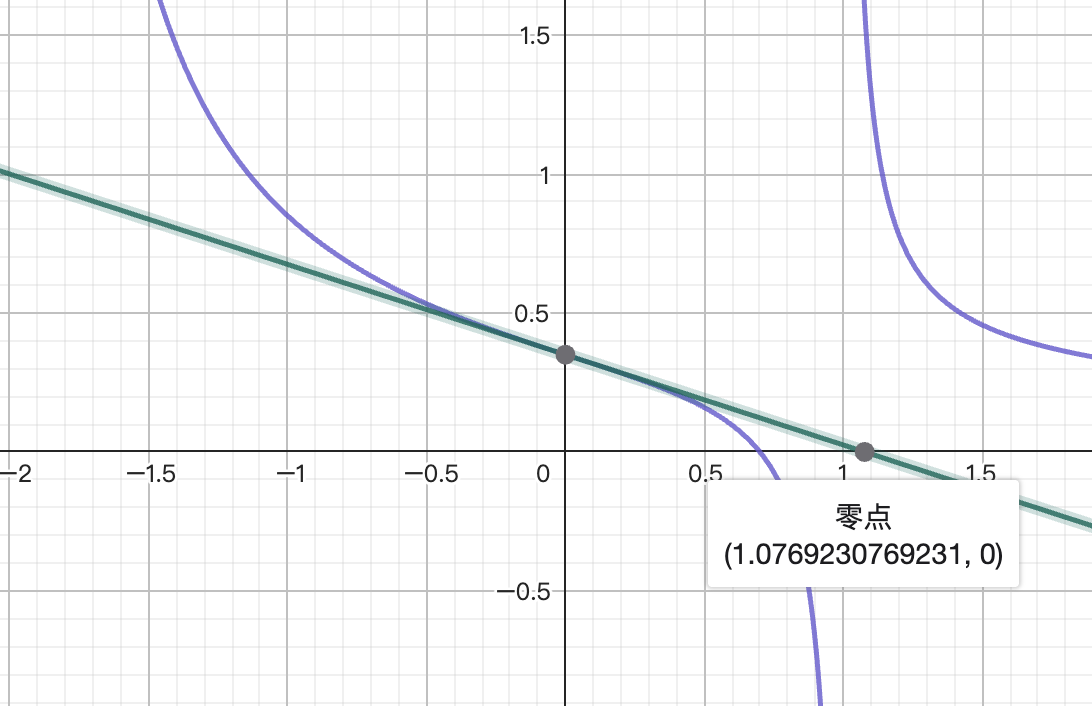
El primer punto de iteración ya está fuera del dominio factible, fuera del dominio de definición de la derivada, y continuar iterando carece de sentido. Esto muestra que el método de Newton ingenuo por sí solo no puede manejar situaciones donde se sale del dominio factible.
La solución es: después de calcular el punto de iteración usando el método de Newton, se debe verificar adicionalmente si está dentro del dominio factible. Si lo está, se itera hasta allí; si no lo está, según su dirección, se toma un punto entre el límite del dominio factible y el punto actual como el siguiente punto de iteración.
Pseudocódigo del Algoritmo
Algoritmo
- Inicializar
- Según las tasas de rendimiento , calcular el dominio factible básico
- Recortar el dominio factible:
- Bucle máximo veces:
- Calcular el siguiente punto
- Si no pertenece a
- Si , tomar
- Si , tomar
- Si la diferencia es menor que el umbral de precisión , salir del bucle.
- Actualizar
- Devolver
Implementación del Código
Desde una perspectiva de programación, una abstracción más adecuada es: supongamos que cada resultado en el conjunto tiene dos atributos, tasa de rendimiento r y peso w. Este espacio de resultados puede ser recorrido, entonces el algoritmo puede escribirse como:
/**
* Calcula el apalancamiento óptimo k y el rendimiento esperado e según el criterio de Kelly.
*
* @param R - Vector de tasas de rendimiento
* @param W - Vector de pesos
* @param lower - Límite mínimo de apalancamiento
* @param upper - Límite máximo de apalancamiento
* @param eps - Precisión de convergencia
* @param max_iter - Número máximo de iteraciones
* @param alpha - Factor de aceleración de convergencia
* @returns Un objeto que contiene el apalancamiento óptimo k y el rendimiento esperado e
*/
export function resolve_k(
R: number[],
W: number[],
lower = -Infinity,
upper = Infinity,
eps = 1e-9,
max_iter = 100,
alpha = 0.9
) {
const n = R.length;
if (n !== W.length)
throw new Error(
"Los vectores de rendimiento y probabilidad deben tener la misma longitud"
);
// Calcular el dominio factible básico K, tal que 1 + k * r > 0
let minK = NaN;
let maxK = NaN;
for (let i = 0; i < n; i++) {
const r = R[i];
if (r === 0) continue;
const k = -1 / r; // Valor crítico
if (r > 0) minK = isNaN(minK) ? k : Math.max(minK, k);
if (r < 0) maxK = isNaN(maxK) ? k : Math.min(maxK, k);
}
if (isNaN(minK)) minK = 0; // Si no hay R positivos, minK toma 0
if (isNaN(maxK)) maxK = 0; // Si no hay R negativos, maxK toma 0
lower = Math.max(lower, minK);
upper = Math.min(upper, maxK);
let sum_w = 0;
for (let i = 0; i < n; i++) {
const w = W[i];
if (w < 0) throw new Error(`El peso[${i}] = ${w} debe ser no negativo`);
sum_w += w;
}
if (sum_w === 0) throw new Error("La suma de los pesos debe ser mayor que cero");
let k = 0;
let it;
for (it = 0; it < max_iter; it++) {
let acc_g1 = 0;
let acc_g2 = 0;
for (let i = 0; i < n; i++) {
const r = R[i];
const w = W[i];
acc_g1 += (w * r) / (1 + k * r);
acc_g2 += (w * r * r) / (1 + k * r) ** 2;
}
const delta_k = acc_g1 / acc_g2;
if (!(Math.abs(delta_k) > eps)) break;
let next_k = k + delta_k;
if (next_k <= lower) {
next_k = lower * alpha + k * (1 - alpha);
} else if (next_k >= upper) {
next_k = upper * alpha + k * (1 - alpha);
}
k = next_k;
}
const lne =
R.reduce((acc, r, i) => acc + W[i] * Math.log(1 + k * r), 0) / sum_w;
const e = Math.exp(lne) - 1;
return { k, e, it, sum_w, lne, upper, lower };
}
Otras Propiedades Matemáticas
Sin restricciones de dominio factible, cuando el rendimiento esperado es positivo, el rendimiento óptimo es positivo
Demostración: Dado que tiene el mismo signo que , el signo de es el mismo que el de . Consideremos la derivada de en : , que en realidad es el rendimiento esperado . Para una cantidad infinitesimal , según la definición de derivada,
Si , entonces existe tal que , es decir, , y el rendimiento óptimo
Q.E.D.
Además, se puede demostrar la siguiente tabla:
| Rendimiento Esperado | Apalancamiento Óptimo | Rendimiento Óptimo |
|---|---|---|
| Positivo | Positivo | Positivo |
| 0 | 0 | 0 |
| Negativo | Negativo | Positivo |
Método de Backtesting Histórico para FSA
Margen de Beneficio Bruto: Gross Profit Margin, GPM
Según el marco de trading descrito, en cada momento se puede calcular el apalancamiento real y el apalancamiento óptimo , y controlar que el apalancamiento real converja hacia el óptimo.
Aquí adoptamos por defecto el método de backtesting con interés simple, porque el modelo de interés compuesto afectaría la estimación posterior de costos. El modelo de interés compuesto generaría cambios muy grandes en el volumen negociado, lo que llevaría a que, una vez alcanzada la capacidad de la estrategia, se produzcan costos de impacto de mercado adicionales, causando que el volumen realmente negociable o los costos se desvíen significativamente de los valores del modelo, distorsionando el backtest. En escenarios reales, la operación de interés compuesto a menudo es controlada subjetivamente, es decir, ajustando subjetivamente el valor neto inicial o el multiplicador de trading para producir un esquema de "interés parcialmente compuesto" entre "interés simple" e "interés compuesto".
Restricción clave: depende solo de la información conocida en los momentos , no existe función de futuro. afecta el tamaño de la posición en el momento .
Para realizar backtesting histórico, primero necesitamos conocer el precio y el volumen de posición neta planificado correspondiente .
A nivel micro, en el momento , al conocer el precio , también conocemos el valor neto y el volumen de posición neta .
Consideremos primero el caso límite: .
Después de un tiempo de análisis despreciable, obtenemos el volumen de posición neta planificado .
El volumen de trading necesario para ajustar la posición es
Posteriormente, hasta el momento , comenzará inmediatamente la colocación de órdenes.
Bajo el supuesto de liquidez suficiente, la ejecución completa ocurrirá al precio , haciendo que . Sea el costo basado en el volumen negociado, entonces el costo es . Además, la posición neta se ve afectada por el cambio de precio, generando ganancias/pérdidas .
En resumen, en el momento :
En el modo de interés simple, el tamaño de la posición y los costos de transacción son proporcionales al valor neto inicial.
Después de tomar una posición, la ganancia/pérdida total (Profit and Loss, PnL) generada por los cambios de precio:
Volumen total negociado (Turnover):
Podemos estimar el costo máximo de transacción que el modelo puede soportar para alcanzar el punto de equilibrio, es decir, el Margen de Beneficio Bruto (Gross Profit Margin, GPM):
Posteriormente, en el trading en tiempo real, cualquier tasa de costo real por debajo de este GPM será rentable. Este GPM también sugiere la capacidad del modelo. Si este GPM es relativamente alto, significa que en tiempo real se pueden utilizar mayores deslizamientos (slippage), aumentando el volumen real negociado.
La tarea del modelo es maximizar el GPM, mientras que la tarea del módulo de trading es lograr ganancias bajo esta restricción de GPM. Específicamente, en el trading posterior en tiempo real, la tarea del módulo de trading es completar la mayor cantidad de volumen negociado posible sin exceder el GPM. El módulo de trading no puede evitar las tasas de comisión inherentes al exchange, que pueden verse afectadas por varios factores, como VIP, reembolsos, Maker/Taker, etc., lo que influye en la tasa de comisión real. Si el GPM del modelo es mayor que la tasa de comisión de un exchange determinado, se puede considerar que es difícil que el modelo sea rentable en ese exchange, necesitando mejoras. Si el módulo de trading considera que la tarea actual no se puede lograr, puede optar por reducir el volumen negociado o no operar, manteniendo una posición cero.
La ganancia final puede considerarse como: Volumen negociado * (GPM - Costo real). Si aumentamos el valor neto inicial, aumentará el volumen negociado, haciendo que la tasa de costo real se acerque continuamente al GPM, hasta que no sea rentable. Sin embargo, según la fórmula, debería existir un problema de optimización de la ganancia. El valor neto inicial correspondiente a esta ganancia máxima es la capacidad del modelo de trading. La evaluación específica requiere un estudio más profundo de la relación entre el volumen negociado y el costo.
Resolución de la Posición
En el trading real, los productos tienen un tamaño mínimo de lote negociable (volume_step), y las posiciones solo pueden negociarse en múltiplos enteros de este paso. Por lo tanto, dado un objetivo de posición en número flotante, no es posible seguir este objetivo al 100%. Por lo tanto, necesitamos redondear este objetivo de posición a una posición negociable.
La Resolución de la Posición (Holding Resolution) es un número entero positivo.
Si para el apalancamiento óptimo aplicamos el método de interés simple y luego mapeamos mediante la resolución, obtenemos la posición objetivo . Sustituyendo en el marco de backtest podemos calcular el MER.
- Si la resolución de la posición = 1, significa que la estrategia solo operará la posición base. Es decir, los valores de la posición objetivo son -1, 0, 1.
- Si la resolución de la posición = 2, significa que la estrategia comienza a necesitar dividir la posición. Los valores de la posición objetivo son -2, -1, 0, 1, 2.
- Si la resolución de la posición = ∞, significa que la estrategia puede ajustar la posición con cualquier precisión. Pero esto no se ajusta a la realidad.
Cuanto menor sea la resolución de la posición, menor será el capital base necesario para la implementación posterior con capital pequeño, pero la información utilizada será más borrosa.
En teoría, la resolución de la posición afecta el volumen negociado; una resolución más baja implica un volumen negociado más bajo (situaciones que requerirían ajuste de posición se convierten en no requeridas). El impacto de la resolución de la posición en el rendimiento no está claro. Empíricamente, si el MER es suficientemente alto y no es sensible a la resolución, significa que se puede proceder directamente al trading en tiempo real.
Módulo de Trading en Tiempo Real
El módulo de trading en tiempo real necesita lograr ganancias bajo la restricción del MER.
Sin embargo, las restricciones para abrir y cerrar posiciones no son consistentes. Al abrir una posición, se puede tolerar que el volumen objetivo no se complete totalmente, pero al cerrar una posición esto no es tolerable. Por lo tanto, al cerrar, las restricciones son más estrictas; en el peor caso, se debe ejecutar con órdenes de mercado, lo que generará mayores comisiones y deslizamiento.
Supongamos que la tasa de costo de una orden de mercado es , entonces al abrir una posición se necesita una tasa de costo de para ser seguro.
Por ejemplo, si MER = 0.02%, el costo de orden de mercado es 0.03%, entonces el costo de apertura debe ser como máximo 0.01%.
Sobre el Espacio de Resultados
Medidas para Cisnes Negros
Un cisne negro se refiere a un evento extremadamente improbable que, sin embargo, ocurre.
- Es imposible estimar la probabilidad de un cisne negro a través de cualquier modelo; cualquier estimación es inútil, su probabilidad es incognoscible.
- Una vez que ocurre un evento cisne negro, genera pérdidas enormes. Por lo tanto, cualquier diseño de espacio de resultados debe defenderse contra eventos cisne negro.
- Cuando ocurre un cisne negro, inevitablemente genera un rendimiento del -100%, es decir, una pérdida total.
- Un cisne negro no puede ser ajustado por ninguna distribución de probabilidad utilizando muestras conocidas. Por lo tanto, es necesario asignar una pseudoprobabilidad ficticia al evento cisne negro.
Supongamos que a partir de muestras existentes, hemos asignado una probabilidad a nuestro espacio de resultados definido .
Necesitamos agregar artificialmente dos eventos cisne negro simétricos: . Donde 0.0013 es la probabilidad fuera de en una distribución normal, aproximadamente 1 en 770 muestras. Cuanto mayor sea la probabilidad asignada a los eventos cisne negro, más conservadora será la estrategia.
Diseñar eventos cisne negro simétricos es para no afectar el rendimiento esperado, evitando cambiar el signo del apalancamiento óptimo y prevenir situaciones donde, originalmente con apalancamiento 0, se juzgue erróneamente que se necesita vender en corto.
Las probabilidades originales deben reducirse en un factor de para garantizar la exhaustividad del nuevo espacio de resultados.
Agregar eventos cisne negro reduce el dominio factible, restringiendo estrictamente la tasa de apalancamiento óptima dentro de . Aún se puede vender en corto, pero no se puede agregar apalancamiento adicional. La inclusión de eventos cisne negro puede prevenir efectivamente el abuso del apalancamiento.
export function withBlackSwan(R: number[], W: number[], Pb = 0.0013) {
const sum_w = W.reduce((acc, cur) => acc + cur, 0);
const w_b = (Pb * sum_w) / (1 - 2 * Pb);
return {
R: R.concat([1, -1]),
W: W.concat([w_b, w_b]),
};
}
Resumen
Para un espacio de resultados dado , los son determinados. Siempre que se pueda estimar la distribución de probabilidad en el espacio de resultados, se puede obtener un apalancamiento óptimo determinista . Si se considera que el sistema de trading debe ser consistente, sus probabilidades deberían ser repetibles. En este contexto, el Análisis de Espectro Completo utiliza información imperfecta de manera sin pérdidas, por lo que no hay ninguna razón para no seguir estrictamente este apalancamiento óptimo.
Algunos sistemas de trading intentan encontrar el resultado de mayor probabilidad y formular un plan de trading basado en ese resultado. Este es un método de máxima verosimilitud. El riesgo de este método es que si la función de verosimilitud es relativamente plana, elegir cualquier interpretación individual no es lo suficientemente precisa. Esta estrategia puede parecer efectiva a veces e inefectiva otras. El Análisis de Espectro Completo no necesita seguir el resultado de mayor probabilidad; puede calcular los rendimientos bajo diferentes resultados y seleccionar la posición óptima. Puede capturar información sutil y tomar decisiones óptimas. Por lo tanto, el Análisis de Espectro Completo reduce enormemente el umbral de calidad de la información a monetizar.
En cuanto a cómo diseñar el espacio de resultados y estimar la distribución de probabilidad, pertenece al contenido de la información misma que necesita ser monetizada, lo cual se discutirá en una próxima ocasión.
