全スペクトル分析法:情報の最適な実現方法
2025-08-10
背景
資産の成長率を最大化するには?
1956年、J.L. Kellyは『A New Interpretation of Information Rate』(情報率の新たな解釈)を発表しました。この論文は、既知の情報を利用して資産の複利成長率を最大化する方法について、ギャンブラーの観点から議論しています。確率論的な手法を用いて賭けの戦略を導く方法を提案しています。しかし、この論文を実際の投資活動に適用するには、いくつかの問題があります:
- 借入レバレッジと空売りを考慮していないため、結論が0〜1の実質レバレッジ範囲に留まっています。
- ギャンブラーが賭けるのは特定の事象記号であり、次にそれが発生すれば配当を得るが、そうでなければ賭け金を失うと仮定しています。しかし、トレーダーは買い(ロング)または売り(ショート)にしか賭けることができず、ロング/ショートに対応する上昇/下落事象は、異なる時間枠において異なる結果と異なる収益率を示します。
- 清算タイミング:ケリーは賭けの終了・清算はギャンブラーの意思では決まらないと仮定しています。しかし、トレーダーはいつでもポジションを決済(退出)するか、継続するかを決定できます。
- 冗長なベイズ的手法:事象の展開は事前確率と条件付き確率に関連すると仮定しています。ベイズ的手法を取り除いても導出される数学的本質には影響せず、難易度を増大させ、論文の公式を直接使用するのは難しく、実際の使用には簡略化が必要です。
我々はケリー論文の確率論的手法を引き継ぎ、投資取引分野に適用可能な実用的な戦略を探求します。
全スペクトル分析法:Full-Spectrum Analysis, FSA
結末空間、最適レバレッジ、最適収益率
ある取引戦略を実行した場合、最終的にはいくつかの異なる結末事象が生じると仮定し、結末空間を とします。 は空ではありません(実際のシナリオでは少なくとも2つの結末が存在します)。
追加の仮定:
- 確定収益率:各結末事象は明確な収益率に対応します。結末 の収益率を とします。
- ✅ 異なる収益率の事象は、異なる結末事象として扱うべきです。例えば、1%の利益と2%の利益は異なります。
- ❌ 明らかに異なる収益率の利益事象を同じ結末にまとめることは、確定収益率の仮定に反します。
- 確定確率:結末 が発生する確率を とします()。
- ✅ 各結末の確率は確定的に評価される必要があります。
- ❌ ある結末が発生する可能性が8割以上(80%〜100%)であると考えることは、確定確率の仮定に反します。
- 排反性:2つの結末が同時に発生することは不可能です。
- ✅ 絶対に同時に発生しない結末事象を設計する必要があります。
- ❌ 結末事象に共通部分が存在する場合(例えば、「20分間ポジションを保有する」事象と「20%下落する」事象が同時に発生する可能性がある場合)、排反性に反します。
- 完全性:すべての結末が発生する確率の合計は100%であり、事前に定義された結末以外の結末は存在しません。つまり、 です。
- ✅ 発生する可能性のあるすべての結末を考慮する必要があります。
- ❌ 結末事象として「20%以上上昇」、「20%以上下落」のみを定義し、「-20%〜20%の間で変動」を定義していない場合、完全性に反します。
- レバレッジ効果:収益率はレバレッジ効果に従います。つまり、 倍のレバレッジを使用する場合、結末 が発生すると、収益率は となり、資産は元の 倍になります。
- ✅ 流動性が十分に高い投資商品はこの特性を満たします。
- ❌ 保有ポジションが大きすぎる場合、流動性の理由から市場インパクトコストが発生し、収益は線形関係に従わなくなります。
結末空間 に対して、期待収益率 Expected Earning Yield を計算できます:
期待収益率の考え方は直感的で、計算も容易です。期待収益率の問題点は:
- 導かれる意思決定が極端で、ポジションなしかフルポジションかのどちらかになり、破産リスクを制御できません。期待収益率が正の場合、たとえ高レバレッジが破産をもたらす可能性があっても、より高い収益率を求めてレバレッジを無限に拡大する傾向があります。
- 複利効果を考慮していません。単一の投資の収益状況のみを考慮しており、市場が繰り返し投資可能であることを考慮していません。実際の投資管理の状況に適合していません。
複合収益率 Compound Earning Yield とは、独立した取引を複数回繰り返した後、単一の取引に均等に割り振った収益率のことです:
最適収益率 Optimal Earning Yield は、異なるレバレッジにおける複合収益率の最大値です:
破産(ゼロ)を避けるためには、すべての結末に対して が満たされる必要があり、これから の基本的な実行可能領域 を導出できます:
上限:
下限:
および常に実行可能な解 、
最適レバレッジとは、実行可能領域 内で複合収益率 を最大化する のことです。
任意の時点で、口座内の実質レバレッジ を計算でき、最適レバレッジ も評価できます。 すべての取引戦略は、最終的に実質レバレッジに対応します。確定的な取引意思決定を行うことは、 の値を決定することと等価です。そして最適レバレッジは理想的なポジション保有に対応します。
これにより、以下の取引フレームワークが得られます:
- 結末空間 を設計する。
- 異なる結末の確率 を継続的に評価する。
- 実質レバレッジ と最適レバレッジ を計算する。
- 実質レバレッジを最適レバレッジに近づけるように制御する。
特殊点
自明点 、つまり「参加しなければ損益は発生しない」。 ポジションを持っていないとき、我々は と決定したことと等価です。どの商品についても、ポジションの有無に関わらず、我々は常に決定を行っています。 空売りは の場合です。もし ならば、追加のレバレッジが必要であることを意味します。
最適化の求解
問題を振り返ると、結末空間 、確率分布 、収益率 、実行可能領域 が既知であり、収益率を最大化するレバレッジ率 を求めることです:
複合収益率を移項整理し、両辺に対数を取ると(単調性は保持されます)、以下が得られます:
ここで、
最適レバレッジの定義によると:
は単調増加関数なので:
の一次導関数、二次導関数を求めます:
二次導関数の各項は非正なので、 です。 の場合に限り となりますが、この場合 となり、収益はなく実質的な意味はありません。それ以外の場合、 です。これは が厳密な凹関数であり、 が厳密に単調減少であることを意味します。 には唯一つの極大点があり、この極大点が最大点です。
下図に示すように、項数がいくつであっても、 の曲線は凹関数です。
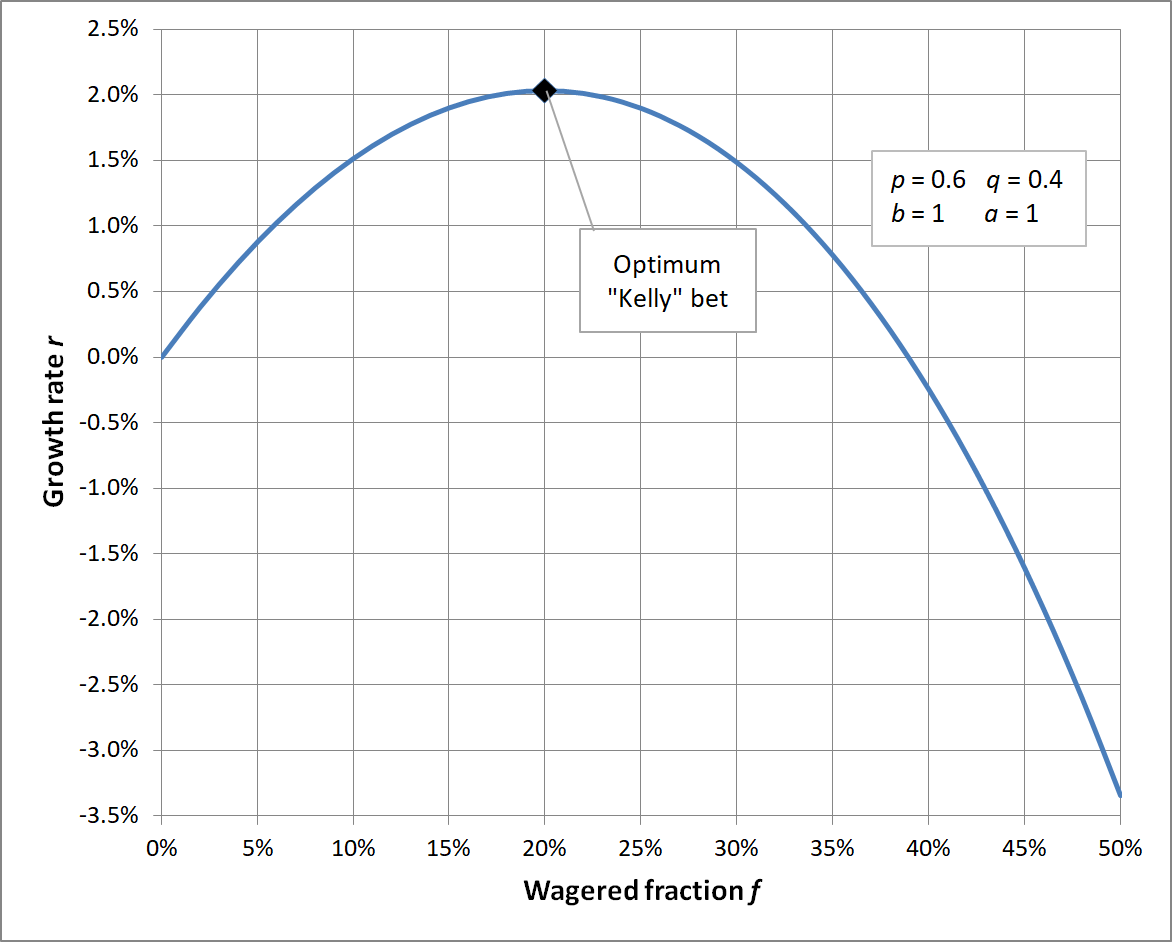
の極大点は、その一次導関数の零点です:
この方程式を整理すると、k に関する多項式方程式に変換できます。 の異なる値が 個存在する場合、上記の多項式方程式の最高次数は です。 アーベル-ルフィニの定理によれば、五次以上の多項式には一般的な根の公式が存在しません。
一般的なケリー公式は、 の特殊な場合です:勝率 、オッズ とします。
| 結末 | 確率 | 収益率 |
|---|---|---|
| 勝 | ||
| 負 |
代入して方程式を得ます:
整理すると、
ケリー公式が得られます。
取引シナリオでは、異なる収益率の結末が無数に存在する可能性があるため、数値解を求めるしかありません。
単変数の厳密な凹関数として、ニュートン法を用いて解を求めるのが最適な選択です。 不動点 から反復を開始するのは良い選択です。厳密な凹関数では、どの点から開始しても同じ結果に収束します。
ニュートン法が実行可能領域を超える場合
潜在的な問題は、ニュートン法で得られた反復点が、問題の実行可能領域を超える可能性があることです。 最小化の例でこの状況を説明します:
これより、
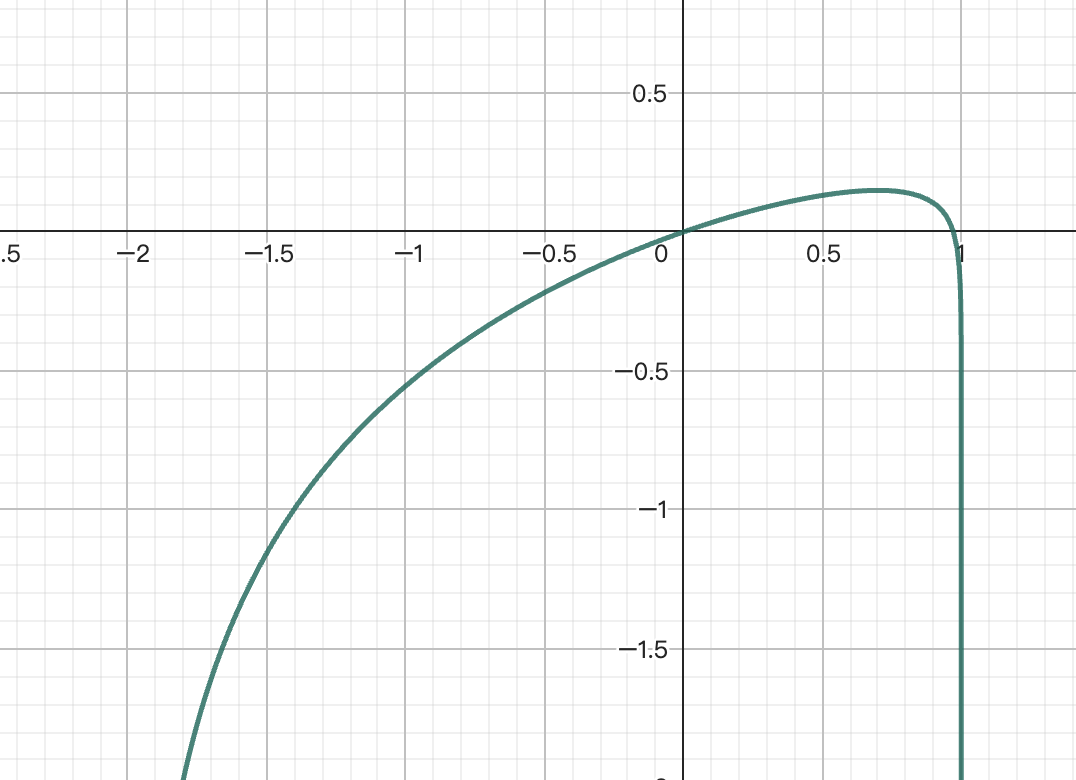
計算により実行可能領域 が得られ、解析的最適レバレッジ ですが、 ニュートン法を使用する場合、最初の反復点は
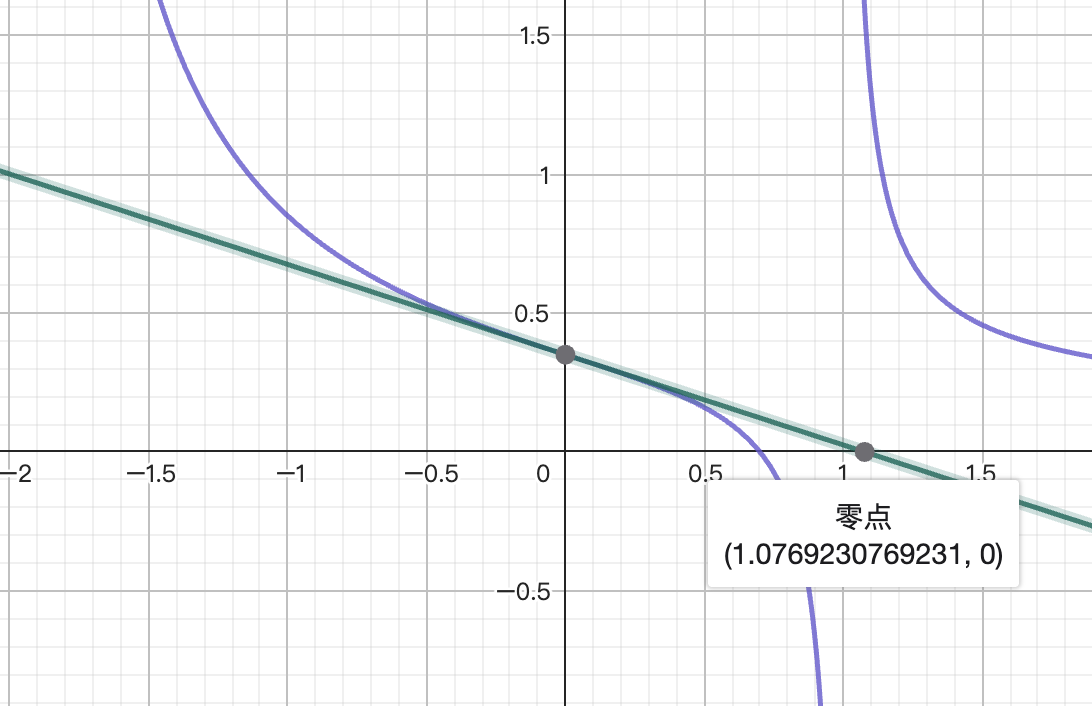
最初の反復点で実行可能領域を超え、導関数の定義域を超えてしまうため、それ以降の反復は意味がありません。これは、単純なニュートン法自体では実行可能領域を超える状況を処理できないことを示しています。
解決方法は、ニュートン法で反復点を計算した後、それが実行可能領域内にあるかどうかを追加で判断することです。領域内であればその点に反復し、領域外であればその方向に応じて、実行可能領域の境界と現在の点との間の点を次の反復点とします。
アルゴリズムの疑似コード
アルゴリズム
初期化
収益率 に基づいて、基本的な実行可能領域 を計算
実行可能領域をクリッピング
最大 回ループ:
次の点を計算
もし が に属さない場合
- もし なら、 とする
- もし なら、 とする
差が精度閾値 より小さければ、ループを抜ける。
更新
を返す
コード実装
プログラミングの観点では、より適切な抽象化は、結末集合の各結末が収益率 r と重み w の2つの属性を持つとすることです。この結末空間は走査可能であり、アルゴリズムは以下のように記述できます:
/**
* ケリー基準に基づき、最適レバレッジ k と期待収益 e を計算します。
*
* @param R - 収益率ベクトル
* @param W - 重みベクトル
* @param lower - 最小レバレッジ制限
* @param upper - 最大レバレッジ制限
* @param eps - 収束精度
* @param max_iter - 最大反復回数
* @param alpha - 収束加速係数
* @returns 最適レバレッジ k と期待収益 e を含むオブジェクト
*/
export function resolve_k(
R: number[],
W: number[],
lower = -Infinity,
upper = Infinity,
eps = 1e-9,
max_iter = 100,
alpha = 0.9
) {
const n = R.length;
if (n !== W.length)
throw new Error(
"Returning and Probability vectors must have the same length"
);
// 基本的な実行可能領域 K を計算 (1 + k * r > 0 となる領域)
let minK = NaN;
let maxK = NaN;
for (let i = 0; i < n; i++) {
const r = R[i];
if (r === 0) continue;
const k = -1 / r; // 臨界値
if (r > 0) minK = isNaN(minK) ? k : Math.max(minK, k);
if (r < 0) maxK = isNaN(maxK) ? k : Math.min(maxK, k);
}
if (isNaN(minK)) minK = 0; // 正の R がない場合、minK を 0 とする
if (isNaN(maxK)) maxK = 0; // 負の R がない場合、maxK を 0 とする
lower = Math.max(lower, minK);
upper = Math.min(upper, maxK);
let sum_w = 0;
for (let i = 0; i < n; i++) {
const w = W[i];
if (w < 0) throw new Error(`Weight[${i}] = ${w} must be non-negative`);
sum_w += w;
}
if (sum_w === 0) throw new Error("Sum of weights must be greater than zero");
let k = 0;
let it;
for (it = 0; it < max_iter; it++) {
let acc_g1 = 0;
let acc_g2 = 0;
for (let i = 0; i < n; i++) {
const r = R[i];
const w = W[i];
acc_g1 += (w * r) / (1 + k * r);
acc_g2 += (w * r * r) / (1 + k * r) ** 2;
}
const delta_k = acc_g1 / acc_g2;
if (!(Math.abs(delta_k) > eps)) break;
let next_k = k + delta_k;
if (next_k <= lower) {
next_k = lower * alpha + k * (1 - alpha);
} else if (next_k >= upper) {
next_k = upper * alpha + k * (1 - alpha);
}
k = next_k;
}
const lne =
R.reduce((acc, r, i) => acc + W[i] * Math.log(1 + k * r), 0) / sum_w;
const e = Math.exp(lne) - 1;
return { k, e, it, sum_w, lne, upper, lower };
}
その他の数学的性質
実行可能領域が制限されない場合、期待収益率が正ならば最適収益率も正
証明: は と符号が同じなので、 と の符号は同じです。 における の導関数を考えます:、これは実際には期待収益率 です。 微小量 に対して、導関数の定義により、
もし ならば、、つまり となる が存在し、最適収益率は
証明終わり。
この他に、以下の表の結論が証明できます:
| 期待収益率 | 最適レバレッジ | 最適収益率 |
|---|---|---|
| 正 | 正 | 正 |
| 0 | 0 | 0 |
| 負 | 負 | 正 |
FSA のヒストリカル・バックテスト手法
粗利益率:Gross Profit Margin, GPM
取引フレームワークで述べたように、各時点で実質レバレッジ と最適レバレッジ を計算し、実質レバレッジを最適レバレッジに近づけるように制御できます。
ここでは、後のコスト推定に複利モデルが影響を与えるため、単利によるバックテスト方式をデフォルトとします。複利モデルは非常に大きな取引高の変動を生み出し、戦略容量に達した後、市場に追加のインパクトコストを発生させ、実際に約定可能な量やコストがモデル値から大きく乖離し、バックテストの信頼性を損なう可能性があります。実際のシナリオでは、複利操作は多くの場合人為的に制御されます。つまり、初期純資産や取引倍数を主観的に調整して、「単利」と「複利」の間の「部分複利」的なスキームを生み出します。
重要な制約: は 時点の既知情報のみに依存し、未来関数は存在しません。 は 時点の保有量に影響を与えます。
ヒストリカル・バックテストを行うには、まず価格 および対応する計画純保有量 を知る必要があります。
ミクロの視点では、 時点において、価格 と同時に、純資産 と純保有量 を知ることができます。
境界条件を考えます:。
無視できるほどの分析時間を経て、計画純保有量 が得られます。
ポジション調整が必要な取引量は
その後、 時点までに、直ちに注文が開始されます。
流動性が十分にあると仮定すると、 の価格で完全に約定し、 となります。 を取引高に基づくコスト率とすると、コストは です。 また、純保有 は価格変動の影響を受け、損益 を生み出します。
以上をまとめると、 時点では:
単利モードでは、保有量と取引コストは初期純資産に比例します。
ポジション保有後、価格変動による総利益(Profit and Loss, PnL):
総取引高:
モデルが収支トントンとなる最大の取引コスト率、つまり粗利益率(Gross Profit Margin, GPM) を推定できます:
その後、実取引では、この GPM を下回る実際のコスト率であれば利益を上げることができます。この GPM はモデルの容量を示唆しており、この GPM が大きいほど、実取引時により大きな取引スリッページを使用し、実際の取引量を増やすことが可能であることを意味します。
モデルの任務は GPM を最大化することであり、取引モジュールの任務はこの GPM 制約下で利益を実現することです。具体的には、その後の実取引において、取引モジュールの任務は、GPM を超えない範囲で、できるだけ多くの取引高を達成することです。取引モジュールは取引所固有の手数料率を回避することはできず、手数料率は VIP、リベート、メイカー/テイカーなどの様々な要因の影響を受ける可能性があります。モデルの GPM がある取引所の手数料率より大きい場合、そのモデルはその取引所で利益を上げるのは難しいと考えられ、モデルの改善が必要です。取引モジュールが現在の任務を達成できないと判断した場合、取引高を減らすか、取引を行わずにポジションをゼロに保つことを選択できます。
最終的な利益は、取引高 * (GPM - 実際のコスト率) と考えることができます。初期純資産を増やすと取引高が増加し、実際のコスト率が GPM に限りなく近づき、利益がなくなるまでになります。しかし、式から判断すると、利益の最適化問題が存在するはずです。この最大利益に対応する初期純資産が取引モデルの容量となります。具体的な評価には、取引高とコストの関係についてさらに深く研究する必要があります。
保有分解能
実際の取引では、商品には最小取引量のステップ(volume_step)があり、ポジションはステップの整数倍でのみ取引できます。 したがって、浮動小数点数の目標ポジションが与えられても、この目標ポジションを100%追跡することはできません。そのため、この目標ポジションを取引可能なポジションに丸める必要があります。
保有分解能, Holding Resolution は、正の整数です。
最適レバレッジ に対して単利法を適用し、分解能マッピングを通じて目標ポジション を得た場合。バックテストフレームワークに代入すると MER を計算できます。
- 保有分解能 = 1 の場合、戦略は基本ポジションのみを取引することを意味します。つまり、目標ポジションの値は -1, 0, 1 です。
- 保有分解能 = 2 の場合、戦略はポジション分割を開始する必要があることを意味します。目標ポジションの値は -2, -1, 0, 1, 2 です。
- 保有分解能 = ∞ の場合、戦略は任意の精度でポジションを調整できることを意味します。しかし、これは実際の状況には適合しません。
保有分解能が低いほど、後の少額での実取引時に必要な基礎資金は少なくなりますが、利用される情報は曖昧になります。
理論的には、保有分解能は取引高に影響を与えます。分解能が低いほど、取引高は低くなります(本来ポジション調整が必要な状況が不要になるため)。保有分解能が収益に与える影響は明確ではありません。経験上、MER が十分に高く、分解能に敏感でない場合、直接実取引に移行できることを意味します。
実取引モジュール
実取引モジュールは、MER 制約下で利益を実現する必要があります。
しかし、建玉(ポジションオープン)と決済(ポジションクローズ)の制約は一致しません。建玉時には目標取引高が完全に約定しなくても許容できますが、決済時にはこれを許容できません。したがって決済時には制約が厳しく、最悪の場合、成行注文で約定させる必要があり、高い手数料とスリッページが発生する可能性があります。
成行注文のコスト率を と仮定すると、建玉時には のコスト率で建玉を行うことが安全です。
例えば MER = 0.02%、成行注文コストが 0.03% の場合、建玉コストは最大 0.01% となります。
結末空間について
ブラック・スワンへの対策
ブラック・スワンとは、極めて発生する可能性が低いが、実際には発生する事象のことです。
- いかなるモデルでもブラック・スワン発生の確率を推定することはできず、ブラック・スワンに対するいかなる推定も無駄であり、その確率は不可知です。
- ブラック・スワン事象が一度発生すると、非常に大きな損失が生じます。 そのため、いかなる結末空間を設計する際にも、ブラック・スワン事象の発生に対する防御が必要です。
- ブラック・スワンが発生した場合、必ず -100% の収益率、つまり全額損失が発生します。
- ブラック・スワンは、既知のサンプルを用いて、いかなる確率分布でも適合させることはできません。 したがって、ブラック・スワン事象に対して擬似的な確率を設定することは必要です。
既存のサンプルから、我々が設定した結末空間 に確率 を割り当てたと仮定します。
人為的に、2つの対称的なブラック・スワン事象を追加する必要があります:。ここで 0.0013 は正規分布における 外の確率で、約770サンプルに1回発生する程度です。ブラック・スワン事象に割り当てる確率が大きいほど、戦略は保守的になります。
対称的なブラック・スワン事象を設計するのは、期待収益率に影響を与えず、最適レバレッジの符号を変更させないためです。これにより、本来レバレッジ0であるべき状況で、誤って空売りが必要と判断される事態を防ぎます。
元の確率は、新しい結末空間全体の完全性を保証するために、 倍に縮小する必要があります。
ブラック・スワン事象を追加すると、実行可能領域が縮小し、最適レバレッジ率は厳密に 内に制限されます。空売りは可能ですが、追加のレバレッジをかけることはできません。ブラック・スワン事象の追加は、レバレッジの乱用問題を効果的に防止できます。
export function withBlackSwan(R: number[], W: number[], Pb = 0.0013) {
const sum_w = W.reduce((acc, cur) => acc + cur, 0);
const w_b = (Pb * sum_w) / (1 - 2 * Pb);
return {
R: R.concat([1, -1]),
W: W.concat([w_b, w_b]),
};
}
まとめ
与えられた結末空間 に対して、 は確定しており、結末空間内の確率分布 を推定できれば、確定的な最適レバレッジ を得ることができます。取引システムが一貫しているべきであると考えるなら、それらの確率は繰り返し可能であるはずであり、この状況下では、全スペクトル分析法は不完全な情報を損なうことなく利用するため、この最適レバレッジを厳密に従わない理由はありません。
一部の取引システムは、最も発生確率の高い結末を求め、その結末に基づいて取引計画を立てようとします。これは最尤法です。この方法のリスクは、尤度関数が比較的平坦な場合、いずれかの解釈を選択することは十分に正確ではないということです。このような戦略は、時には有効で時には無効に見えるでしょう。一方、全スペクトル分析法は最も確率の高い結末に従う必要はなく、異なる結末における収益を計算し、最適なポジションを選択できます。それは微妙な情報を捉え、最適な意思決定を行うことができます。したがって、全スペクトル分析法は、情報を実現するための品質のハードルを大幅に下げます。
結末空間を設計し、確率分布を推定する方法については、実現されるべき情報そのものの内容に属し、次回に譲ります。
